Memory usage in Spark largely falls under one of two categories: execution and storage. As spark jobs are run inside JVM, so it’s important to understand JVM memory management first.
Java Memory Management
In Java architecture there are three basic components:
1-Java Development Kit– JDK is a software development environment used for java applications. It holds JRE, a compiler, an interpreter and several development kits in it.
2-Java Runtime Environment-JRE provides an environment in which Java programmes are executed, JRE takes our code and integrates it with required libraries.
3-Java Virtual Machine-JVM is an abstract machine that provides an environment in which bytecode is executed. this machine has a memory management system. It has three basic components
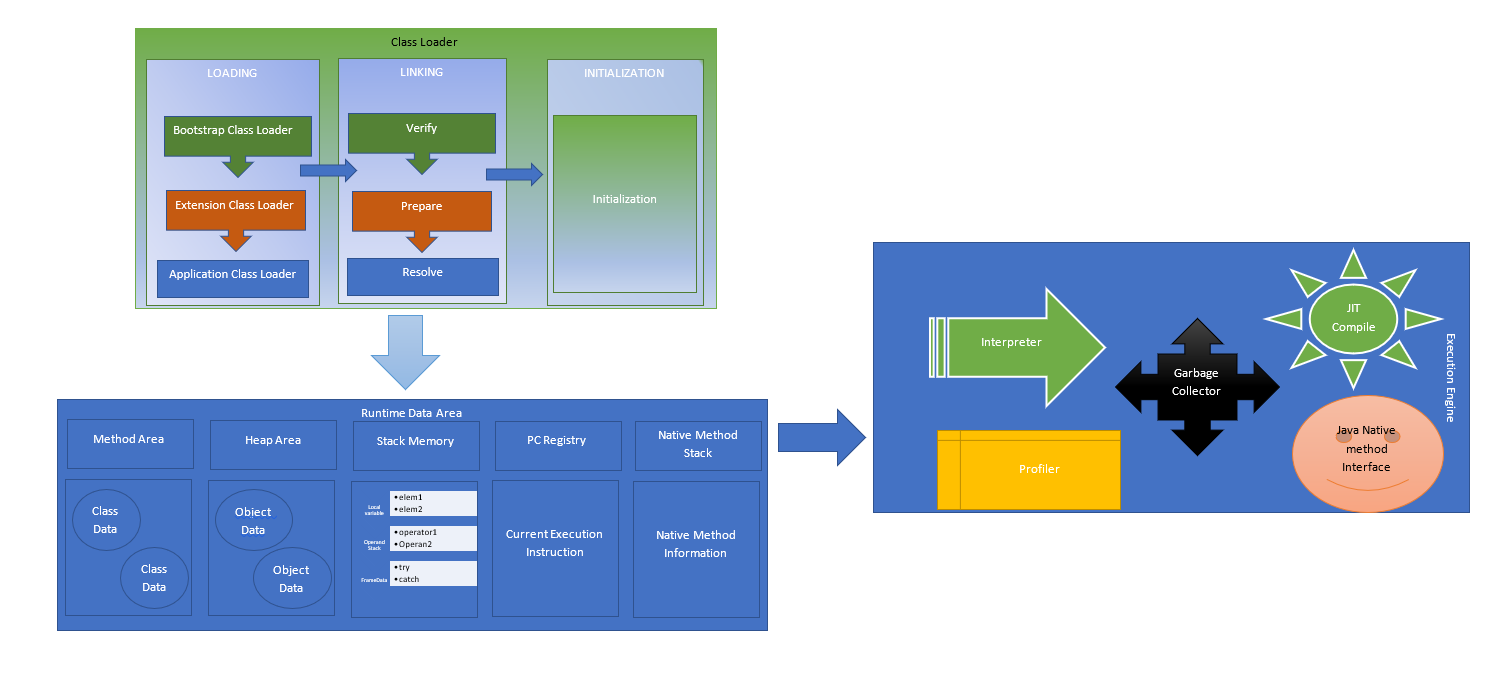
- ClassLoader: It has three phases: Loading, Linking and Initializing.
- Loading
- Bootstrap: Responsible for loading runtime jars. RT.jar
- Application: Application-specific jars.
- Extension—>/jre/lib/ext/, provide precompiled class file available to JVM.
- Linking
- Verify: bytecode class files are verified
- Prepare: memory is available to static variables
- resolve: symbolic references are replaced by actual values.
- Initialization: static values are initialised and also execute the static initialiser.
- Loading

- Runtime Data Area: JVM needs a memory area to load the files and run. It has different memory areas for different code types.
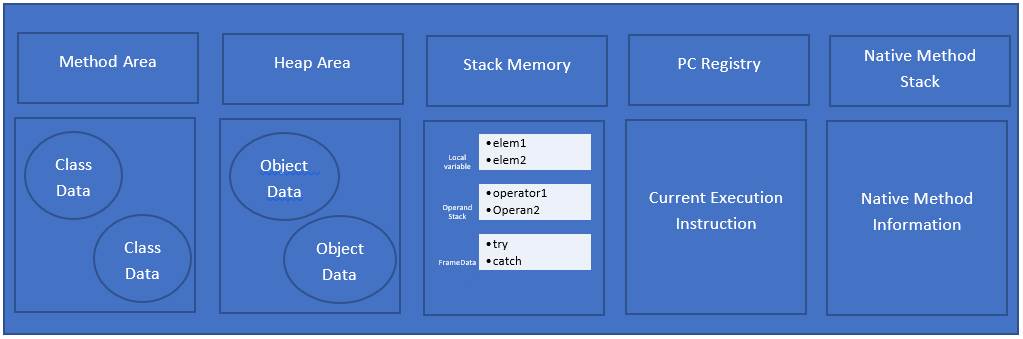
- Execution engine: This converts byte code to machine code. The interpreter runs code line by line, JIT compiler he’s in generates intermediate code when repeated method calls occur.Java Native method interface interacts with native libraries and makes it available for the JVM execution engine. The profiler finds the hotspot and method which call repeatedly.
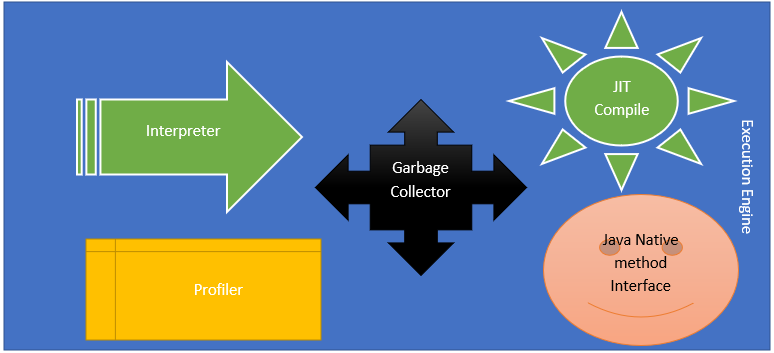
JIT Compiler performs the following steps:
1)-Intermediate code Generation
2)-Code Optimization
3)-Target Code Generation
4)-Profiler.
Thus the JVM has three components, Classloader, Runtime Data Area and Execution Engine.
Spark Memory Management
Memory usage in Spark largely falls under one of two categories: execution and storage. Execution memory refers to that used for computation in shuffles, joins, sorts and aggregations, while storage memory refers to that used for caching and propagating internal data across the cluster. In Spark, execution and storage share a unified region (in orange colour).
The Total Driver Memory is sum of following
1-spark.driver.memory =4 Gb
2-spark.driver.memoryOverhead =0.1
The total executor memory is the sum of following :
1-Overhead Memory: Saprk.executor.memoryOverhead =10% (Non-JVM Memory)
2-heap Memory: spark.executor.memory ~8Gb (JVM Memory)
3-Off-Heap Memory: spark.memory.OffHeap.size
4-Pyspark Memory:spark.executor.pyspark.memory
The driver will ask for above memory container from the yarn. from the above example it will ask for 8.8 gb of container memory (8gb +10% of 8Gb). (JVM and non -JVM memory)
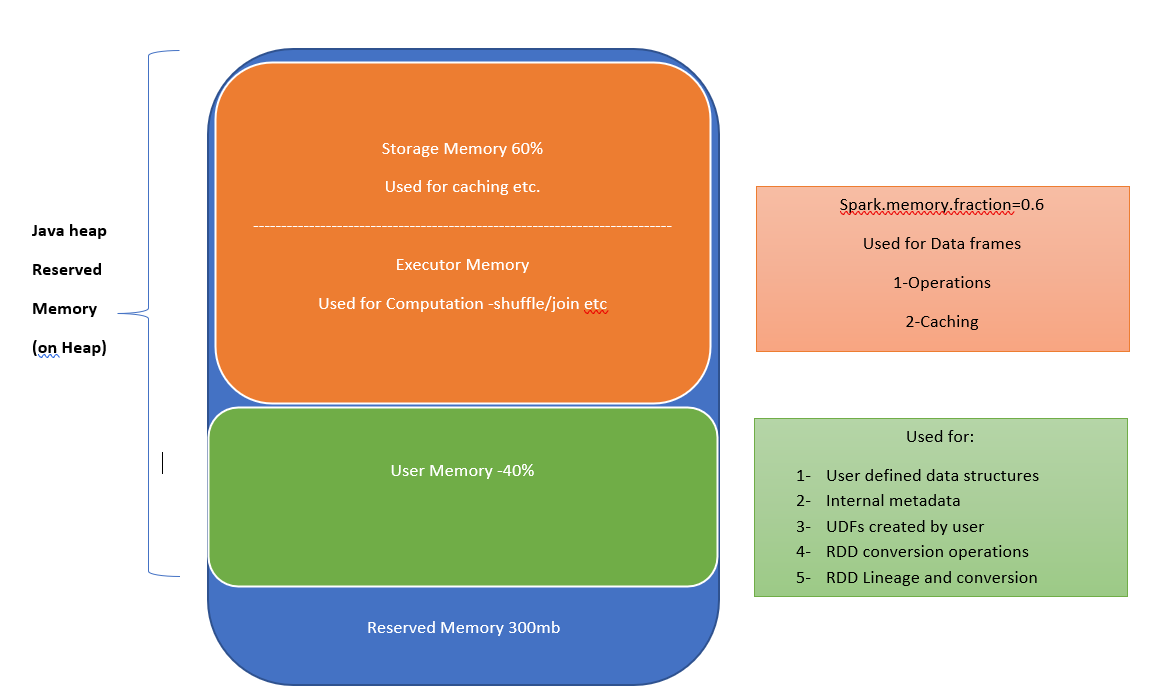
lets Suppose 8 gb of executor memory and 4 CPU core. This 8gb will be divided into 3 parts.
Reserved Memory=300mb
User memory=3080 mb
Sark Memory=4620 mb
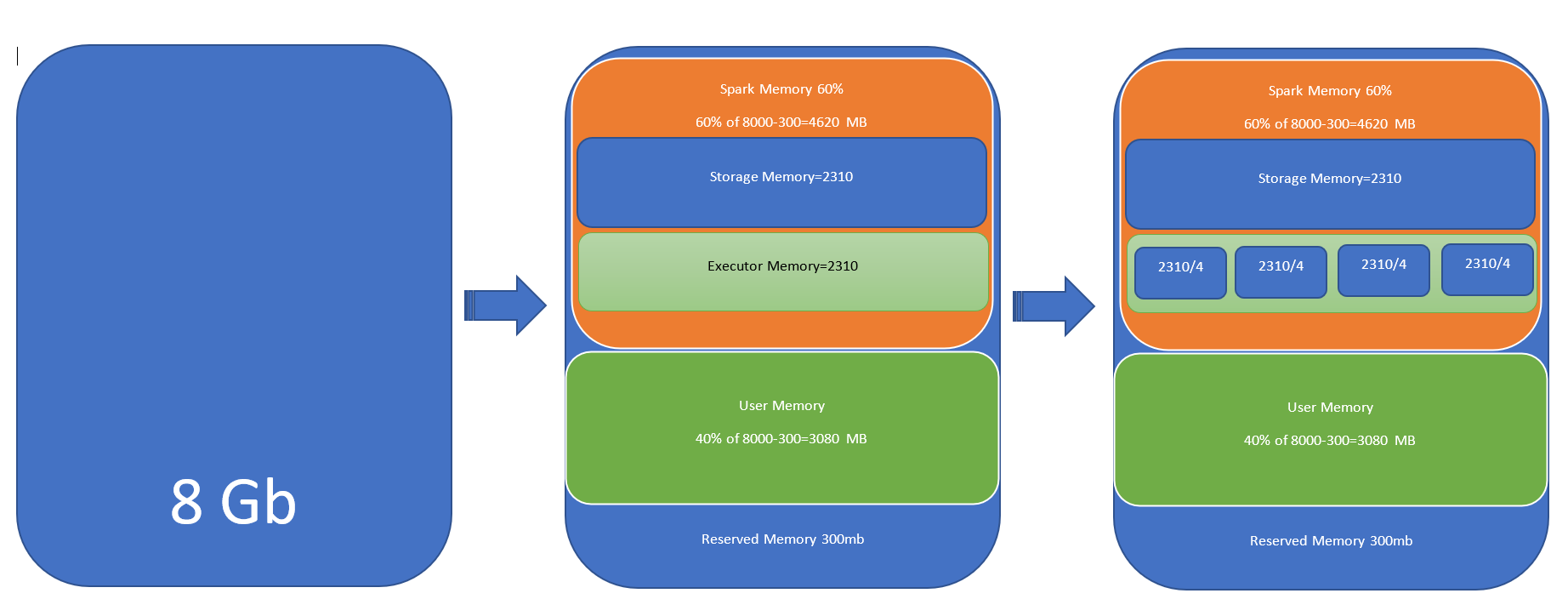
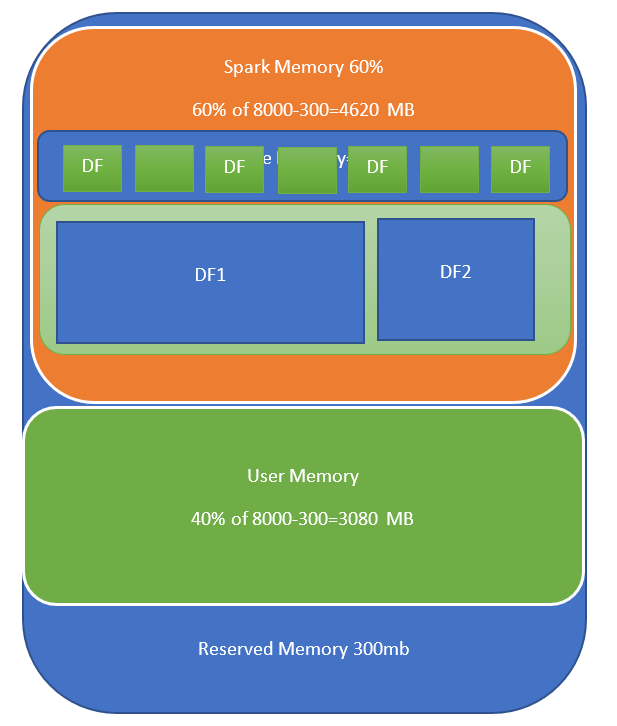
After spark 1.6 , we have more unified memory management, this is a fair memory management, lets suppose if we have two active task then two will share the Executor memory. It can also allocate memory from the storage memory.
We can manage spark memory by spark.memory.storageFraction=0.3 for 30%
So important spark memory configurations are:
1-spark.executor.memoryOverhead
2-spark.executor.memory
3-spark.memory.fraction
4-spark.memory.storageFraction
5-spark.executor.cores