
- Apache Spark is an open-source distributed general-purpose cluster-computing framework.
- Apache Spark is a lightning-fast unified analytics engine for big data and machine learning. It was originally developed at UC Berkeley in 2009.
- When a cluster, or group of machines, pools the resources of many machines together allowing us to use all the cumulative resources as if they were one. Now a group of machines alone is not powerful, you need a framework to coordinate work across them. Spark is a tool for just that, managing and coordinating the execution of tasks on data across a cluster of computers.
Spark Application
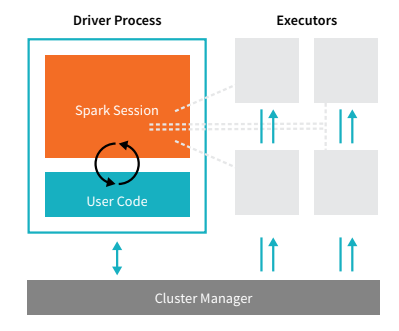
Spark Applications consist of a driver process and a set of executor processes. The driver process runs your main() function sits on a node in the cluster and is responsible for three things: maintaining information about the Spark Application; responding to a user’s program or input; and analyzing, distributing, and scheduling work across the executors (defined momentarily).
Spark Applications consist of a driver process and a set of executor processes. The driver process runs your main()
function sits on a node in the cluster and is responsible for three things: maintaining information about the Spark
Application; responding to a user’s program or input; and analyzing, distributing, and scheduling work across the
executors (defined momentarily).
Languages
Spark’s language APIs allow you to run Spark code from other languages like: Python, Scala, Java, SQL, R
The Spark Session
We control our Spark Application through a driver process. This driver
process manifests itself to the user as an object called the SparkSession. The SparkSession instance is the way. Spark executes user-defined manipulations across the cluster. There is a one to one correspondence between a SparkSession and a Spark Application. In Scala and Python, the variable is available as a spark when you start up the console.
The Spark Context
SparkContext is the entry point of Spark functionality. The most important step of any Spark driver application is to generate SparkContext. It allows your Spark Application to access Spark Cluster with the help of Resource Manager.
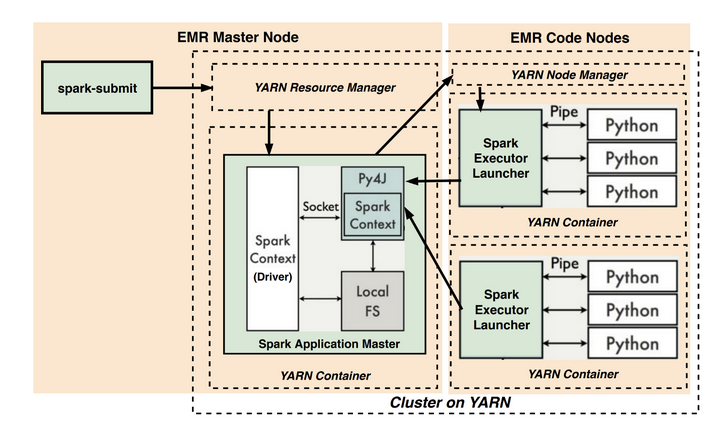
If you see the above figure, the python was called by JVM which is outside of the process so it makes the process slow, but with the launch of spark 2.0, some changes happened. but before moving into 2.0 let us understand what happened before that.
RDD, DATA FRAMES, DATASET
- RDD – The RDD APIs have been on Spark since the 1.0 release.
- DataFrames – Spark introduced DataFrames in Spark 1.3 release.
- DataSet – Spark introduced Dataset in Spark 1.6 release.
RDD (Resilient Distributed Dataset) is the fundamental data structure of Apache Spark which are an immutable collection of objects which computes on the different node of the cluster. Each and every dataset in Spark RDD is logically partitioned across many servers so that they can be computed on different nodes of the cluster.
DataFrame is an immutable distributed collection of data. Unlike an RDD, data is organized into named columns, like a table in a relational database. Designed to make large data sets processing even easier, DataFrame allows developers to impose a structure onto a distributed collection of data, allowing higher-level abstraction.
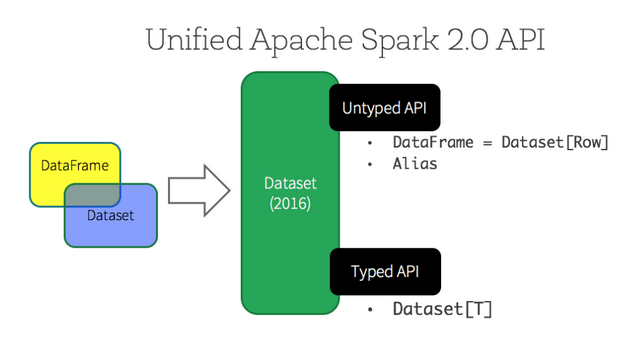
Dataset takes on two distinct APIs characteristics: a strongly-typed API and an untyped API, Conceptually, consider DataFrame as an alias for a collection of generic objects Dataset[Row], where a Row is a generic untyped JVM object. Dataset, by contrast, is a collection of strongly-typed JVM objects, dictated by a case class you define in Scala or a class in Java.
| Language | Main Abstraction |
|---|---|
| Scala | Dataset[T] & DataFrame (alias for Dataset[Row]) |
| Java | Dataset[T] |
| Python* | DataFrame |
| R* | DataFrame |
Partitions
In order to allow every executor to perform work in parallel, Spark breaks up the data into chunks, called partitions. A
partition is a collection of rows that sit on one physical machine in our cluster. A DataFrame’s partitions represent how
the data is physically distributed across your cluster of machines during execution. If
Transformations
In Spark, the core data structures are immutable meaning they cannot be changed once created. This might seem like a strange concept at first if you cannot change it, how are you supposed to use it? In order to “change” a DataFrame, you will have to instruct Spark how you would like to modify the DataFrame you have into the one that you want. These instructions are called transformations.
Transformations are of two types:
- Narrow Transformation: Transformations consisting of narrow dependencies (we’ll call them narrow transformations) are those where each input partition will contribute to only one output partition.
- Wide Transformation: A wide dependency (or wide transformation) style transformation will have input partitions contributing to many output partitions.
Lazy Evaluation
Lazy evaluation means that Spark will wait until the very last moment to execute the graph of computation instructions. In Spark, instead of modifying the data immediately when we express some operation, we build up a plan of transformations that we would like to apply to our source data. Spark, by waiting until the last minute to execute the code, will compile this plan from your raw, DataFrame transformations, to an efficient physical plan that will run as efficiently as possible across the cluster.
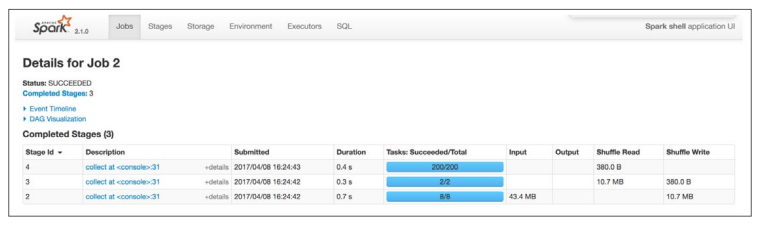
SPARK UI
During Spark’s execution of the previous code block, users can monitor the progress of their job through the Spark UI. The Spark UI is available on port 4040 of the driver node. If you are running in the local mode this will just be:
http://localhost:4040.
References: