CDH is Cloudera’s 100% open-source platform distribution, including Apache Hadoop, and built specifically to meet enterprise demands.
Cloudera Manager is available in the following releases:Cloudera Manager 5.16.2 is the current release of Cloudera Manager 5.16. Cloudera Manager 5.15.2. 5.14.4, 5.13.3, 5.12.2, 5.11.2, 5.10.2, 5.9.3, 5.8.5, 5.7.6, 5.6.1, 5.5.6, 5.4.10, 5.3.10, 5.2.7, 5.1.6, and 5.0.7 are previous stable releases of Cloudera Manager 5.14, 5.13, 5.12, 5.11, 5.10, 5.9, 5.8, 5.7, 5.6, 5.5, 5.4, 5.3, 5.2, 5.1, and 5.0 respectively.
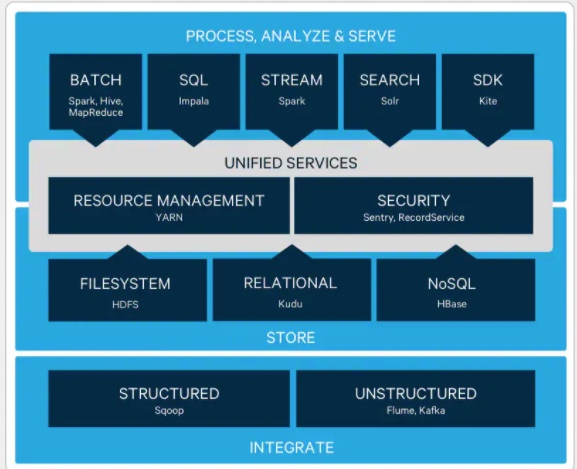
The main Projects of CDH
- Apache Hadoop (Core).
- Apache Accumulo
- Apache Flume
- Apache Sqoop
- Apache HBase
- Apache Impala
- Apache Kafka
- Apache Pig
- Apache Sentry
- Apache Search
- Apache Spark
- Apache Hive
- HUE
A detailed version of CDH:
| CDH | February 1, 2021, all downloads of CDH and Cloudera Manager require a username and password and use a modified URL | ||
| CHD1.X | |||
| CHD2.X | |||
| CHD3.X | End of Maintenance (EOM) on June 20, 2013. | ||
| CHD4.X | End of Maintenance (EOM) on August 9, 2015. | ||
| CDH5 | |||
| CDH5 | Lily HBase Indexer | Lily HBase Indexer provides the ability to quickly and easily search for any content stored in HBase. It allows you to quickly and easily index HBase rows into Solr, | |
| Cloudera Search | 1.0.0-cdh5.0.0 | Cloudera Search is Apache Solr fully integrated in the Cloudera platform, taking advantage of the flexible, scalable, and robust storage system and data processing frameworks included in Cloudera Data Platform (CDP). | |
| Apache Solr | 4.4.0-cdh5.0.0 | ||
| Kite SDK | 0.10.0-cdh5.0.0 | The Kite Data module is a set of APIs for interacting with data in Hadoop, specifically direct reading and writing of datasets in storage subsystems such as the Hadoop Distributed FileSystem (HDFS). | |
| Apache Avro | 1.7.5-cdh5.0.0 | Apache Avro™ is a data serialization system. | |
| Apache Crunch | 0.9.0-cdh5.0.0 | ||
| Apache Spark | 0.9.0-cdh5.0.0 | ||
| Llama | 1.0.0-cdh5.0.0 | Llama is a Yarn Application Master that mediates the management and monitoring | |
| of cluster resources between Impala and Yarn. | |||
| Llama provides a Thrift API for Impala to request and release allocations | |||
| outside of Yarn-managed container processes. | |||
| Parquet | 1.2.5-cdh5.0.0 | ||
| Apache Sentry | 1.2.0-cdh5.0.0 | Apache Sentry™ is a system for enforcing fine grained role based authorization to data and metadata stored on a Hadoop cluster. | |
| Apache Sqoop2 | 1.99.3-cdh5.0.0 | Note: Sqoop 2 is being deprecated. Cloudera recommends using Sqoop 1. | |
| DataFu | 1.1.0-cdh5.0.0 | Apache DataFu Pig is a collection of useful user-defined functions for data analysis in Apache Pig. This library was open sourced in 2010 and continues to receive contributions, having reached 1.0 in September, 2013. It has been used by production workflows at LinkedIn since 2010. | |
| Apache Whirr | 0.9.0-cdh5.0.0 | Apache Whirr is a set of libraries for running cloud services. | |
| Whirr provides: | |||
| A cloud-neutral way to run services. You don’t have to worry about the idiosyncrasies of each provider. | |||
| A common service API. The details of provisioning are particular to the service. | |||
| Apache Mahout | 0.8-cdh5.0.0 | Apache Mahout(TM) is a distributed linear algebra framework and mathematically expressive Scala DSL designed to let mathematicians, statisticians, and data scientists quickly implement their own algorithms. Apache Spark is the recommended out-of-the-box distributed back-end, or can be extended to other distributed backends. Mathematically Expressive Scala DSL Support for Multiple Distributed Backends (including Apache Spark) Modular Native Solvers for CPU/GPU/CUDA Acceleration | |
| Apache Oozie | 4.0.0-cdh5.0.0 | Workflow | |
| Apache Flume | 1.4.0-cdh5.0.0 | Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. | |
| Apache Pig | 0.12.0-cdh5.0. | Like Hive | |
| Apache Sqoop 1 | 1.4.4-cdh5.0.0 | Apache Sqoop(TM) is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases. | |
| Apache ZooKeeper | 3.4.5-cdh5.0.0 | ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. | |
| Apache HBase | 0.96.1.1-cdh5.0.0 | Use Apache HBase™ when you need random, realtime read/write access to your Big Data. | |
| Apache Hive | 0.12.0-cdh5.0.0 | Query HDFS | |
| Apache Hadoop MRv1 | 2.3.0-mr1-cdh5.0.0 | ||
| Apache Hadoop | 2.3.0-cdh5.0.0 | ||
| CDH5 | Apache Crunch | 0.11.0-cdh5.2.6 | The Apache Crunch Java library provides a framework for writing, testing, and running MapReduce pipelines. Its goal is to make pipelines that are composed of many user-defined functions simple to write, easy to test, and efficient to run. |
| Apache Crunch moved to the Apache Attic in July of 2020 and is no longer actively developed. | |||
| What’s New | Link |
CHD moved from 5 to 6 with a major change of Hadoop3X. There are many feature enhancements and changes across the platform related to enhanced capabilities, performance, and security. We can have a look into the current component versions.
| CDH 6.3.4 Packaging | |
| Component | Component Version |
| Apache Avro | 1.8.2 |
| Apache Flume | 1.9.0 |
| Apache Hadoop | 3.0.0 |
| Apache HBase | 2.1.4 |
| HBase Indexer | 1.5 |
| Apache Hive | 2.1.1 |
| Hue | 4.4.0 |
| Apache Impala | 3.2.0 |
| Apache Kafka | 2.2.1 |
| Kite SDK | 1.0.0 |
| Apache Kudu | 1.10.0 |
| Apache Solr | 7.4.0 |
| Apache Oozie | 5.1.0 |
| Apache Parquet | 1.9.0 |
| Parquet-format | 2.4.0 |
| Apache Pig | 0.17.0 |
| Apache Sentry | 2.1.0 |
| Apache Spark | 2.4.0 |
| Apache Sqoop | 1.4.7 |
| Apache ZooKeeper | 3.4.5 |
| What’s New | Link |

Another flavor was Hortonworks, formed in June 2011 as an independent company. The Hortonworks Data Platform (HDP) product included Apache Hadoop and was used for storing, processing, and analyzing large volumes of data. They have a variety of products
| Official Apache versions for HDP 3.0.0: | Refer |
| Apache Accumulo 1.7.0 | With Apache Accumulo, users can store and manage large data sets across a cluster. Apache Accumulo® is a sorted, distributed key/value store that provides robust, scalable data storage and retrieval. |
| Apache Atlas 1.0.0 | Atlas is a scalable and extensible set of core foundational governance services – enabling enterprises to effectively and efficiently meet their compliance requirements within Hadoop and allows integration with the whole enterprise data ecosystem. |
| Apache Calcite 1.16.0 | Apache Calcite is an open source framework for building databases and data management systems. It includes a SQL parser, an API for building expressions in relational algebra, and a query planning engine. As a framework, Calcite does not store its own data or metadata, but instead allows external data and metadata to be accessed by means of plug-ins. |
| Apache DataFu 1.3.0 | DataFusion is an in-memory query engine for the Rust implementation of Apache Arrow. |
| Apache Druid 0.12.1 (incubating) | Apache Druid is a high performance real-time analytics database. |
| Apache Hadoop 3.1.1 | |
| Apache HBase 2.0.0 | |
| Apache Hive 3.1.0 | |
| Apache Kafka 1.1.1 | |
| Apache Knox 1.0.0 | The Apache Knox™ Gateway is an Application Gateway for interacting with the REST APIs and UIs of Apache Hadoop deployments. The Knox Gateway provides a single access point for all REST and HTTP interactions with Apache Hadoop clusters. |
| Apache Livy 0.5.0 | Livy enables programmatic, fault-tolerant, multi-tenant submission of Spark jobs from web/mobile apps (no Spark client needed). So, multiple users can interact with your Spark cluster concurrently and reliably. |
| Apache Oozie 4.3.1 | Oozie is a workflow scheduler system to manage Apache Hadoop jobs. Oozie Workflow jobs are Directed Acyclical Graphs (DAGs) of actions. |
| Apache Phoenix 5.0.0 | Apache Phoenix enables OLTP and operational analytics in Hadoop for low latency applications by combining the best of both worlds: the power of standard SQL and JDBC APIs with full ACID transaction capabilities and the flexibility of late-bound, schema-on-read capabilities from the NoSQL world by leveraging HBase as its backing store Apache Phoenix is fully integrated with other Hadoop products such as Spark, Hive, Pig, Flume, and Map Reduce. |
| Apache Pig 0.16.0 | |
| Apache Ranger 1.1.0 | Apache Ranger has the following goals: Centralized security administration to manage all security related tasks in a central UI or using REST APIs. Fine-grained authorization to do a specific action and/or operation with Hadoop component/tool and managed through a central administration tool Standardize authorization method across all Hadoop components. |
| Apache Spark 2.3.1 | |
| Apache Sqoop 1.4.7 | |
| Apache Storm 1.2.1 | Apache Storm is a free and open source distributed realtime computation system. Apache Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing. Apache Storm is simple, can be used with any programming language, and is a lot of fun to use! |
| Apache Tez 0.9.1 | The Apache TEZ® project is aimed at building an application framework that allows for a complex directed-acyclic-graph of tasks for processing data. It is currently built atop Apache Hadoop YARN. |
| Apache Zeppelin 0.8.0 | |
| Apache ZooKeeper 3.4.6 | ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. |
In October 2018, Hortonworks and Cloudera announced they would be merging in an all-stock merger of equals.[8] After the merger, the Apache products of Hortonworks became Cloudera Data Platform.