This is the story of a person found at JORDAN border, the country is surrounded by 5 neighbors, so how can we find the person belong to which country. KNN plays a vital role here,
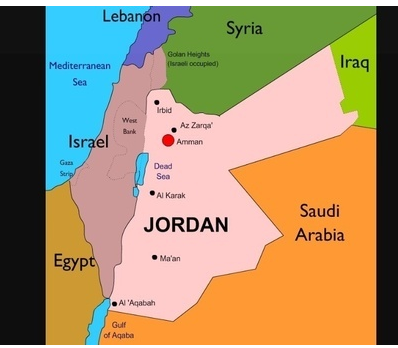
KNN is a algorithm which stores the whole model, i.e. it will never make any function. It will check the person with N numbers of countries who are neighbor to it. This algorithm has following names as it consider the whole sample set.
1-Instance-Based Learning
2-Lazy Learner
3-Non-Parametric
It is used for classification as well as regression problems. It works good for small data sets but hold problem when the dimensions increases and suffer from “Curse of Dimensionality “
Lets Take the problem of Iris Data set,
#Load Basic Libraries
importnumpy as np
import pandas aspd
fromsklearn .datasets import load_iris
import seaborn assns
iris=load_iris()
iris.data.shape–>150,4–>means 150 rows and 4 column
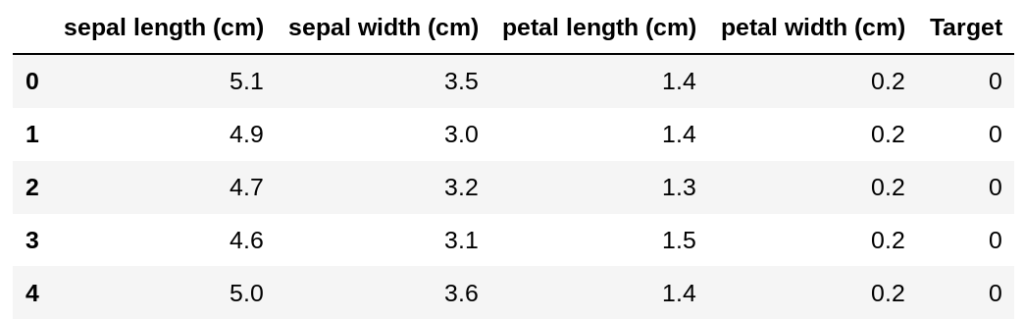
We can create a data frame like this,
df=pd.DataFrame(iris.data,columns=iris.feature_names)
df['Target']=iris.target
Output:
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(5)
#The arguements specify to return the Fast 5 most among the #dataset
nn.fit(iris.data)
or
nn.fit(df.iloc[:,:-1])
Output:
NearestNeighbors(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
radius=1.0)
The distance is of many types , please refer: here
In Order to predict a sample:
sample = np.array([[5.4,2,2,2.3]])
nn.kneighbors(sample)
Output:
(array([[1.6673332 , 1.90525589, 1.94679223, 2.02484567, 2.09523268]]), array([[98, 93, 57, 60, 79]]))
print(df.ix[[98, 93, 23, 60, 79],])
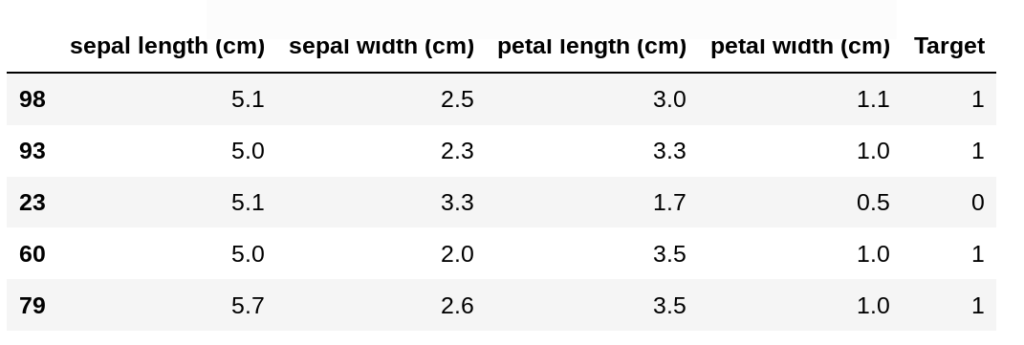
So, 4 neighbors show it belongs to class1 and sample 23 states it belongs to class 0.
The probability of class is defines as:
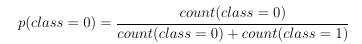
Hi! I could have sworn I’ve been to this website before but after checking through some of the post I realized it’s new to me. Anyhow, I’m definitely glad I found it and I’ll be book-marking and checking back frequently!
I am now not sure where you are getting your info, however good topic. I must spend a while studying much more or working out more. Thank you for wonderful information I used to be on the lookout for this information for my mission.