Twitter is an American microblogging and social networking service on which users post and interact with messages known as “tweets”. Registered users can post, like, and retweet tweets, but unregistered users can only read them.
Let’s talk about the architecture of Twitter, it is microservice architecture. Before deep-diving into the architecture have a look into requirements. As of the first quarter of 2019, Twitter averaged 330 million monthly active users, handles 300K QPS to generate timelines and a firehose that churns out 22 MB/sec. 400 million tweets a day flow through the system and it can take a few seconds for a tweet to flow from Keanu Reeves finger to his 12.3 K followers. Daily usage increased threefold to 60,000 tweets.
In order to achieve the above requirement, Twitter is using the following architecture.

Twitter uses hundred of tools and services like Redis, Apache storm, Earlybird but it is using a very unique FANOUT service. Fanout is a service that updates entries for followers all the tweets that come in and place them in the Redis cluster with the replication factor of three.
FlockDB is a distributed graph database( we can compare it with Neo4j) for storing adjacency lists, with goals of supporting:
- a high rate of add/update/remove operations
- potentially complex set arithmetic queries
- paging through query result sets containing millions of entries
- ability to “archive” and later restore archived edges
- horizontal scaling including replication
- online data migration
So, Twitter keeps a list of arrays, which keeps tweet_id, user_id, other_info. This list is for a single user and it keeps a list of 800 tweet_ids(max)/user. FLOCK holds the list of followers and following. Once a tweet comes, Fanout Deamon queries twitter by “Social graph service”-Flock. If I follow 1000 users and 2000 users follow me, it’s the fanout service that deals with this problem. Fanout Deamon query FLOCK for tweet_id, user_id, and bytes.
When we login we can only see the list of tweets against my timeline. Twitter keeps this list in-memory for all active users in order to give the output fast. There is a separate timeline service that hits a user timeline, but not his home timeline. So, as someone tweet, this Fanout Deamon, query Flock and update the tweet_id inside the array. it’s a straightforward process. In order to make the performance fast, Twitter used Gizmoduck and tweetyPie service.
Twitter has also a lot of different storages.
MySQL & Manhattan as the primary data stores for storing user data.
The engineering team at Twitter has also built a scalable MySQL database service framework called Mysos. It is based on Apache Mesos. Mesos enables Mysos to schedule, monitor & communicate with MySQL instances in the cluster.MySQL instances were sharded with the help of a framework for creating distributed datastores called Gizzard. The gizzard is a framework for Sharding strategies. It often involves two techniques: partitioning and replication.
Memcache, Redis for caching. Twitter built Twemcache, a custom version of Memcache suited for large scale production deployment.
FlockDB for storing social graph
MetricsDB for storing platform data metrics
Blobstore for storing images, videos & large binary objects.
Twitter uses hundreds of microservice to handle the communication and request from the users.
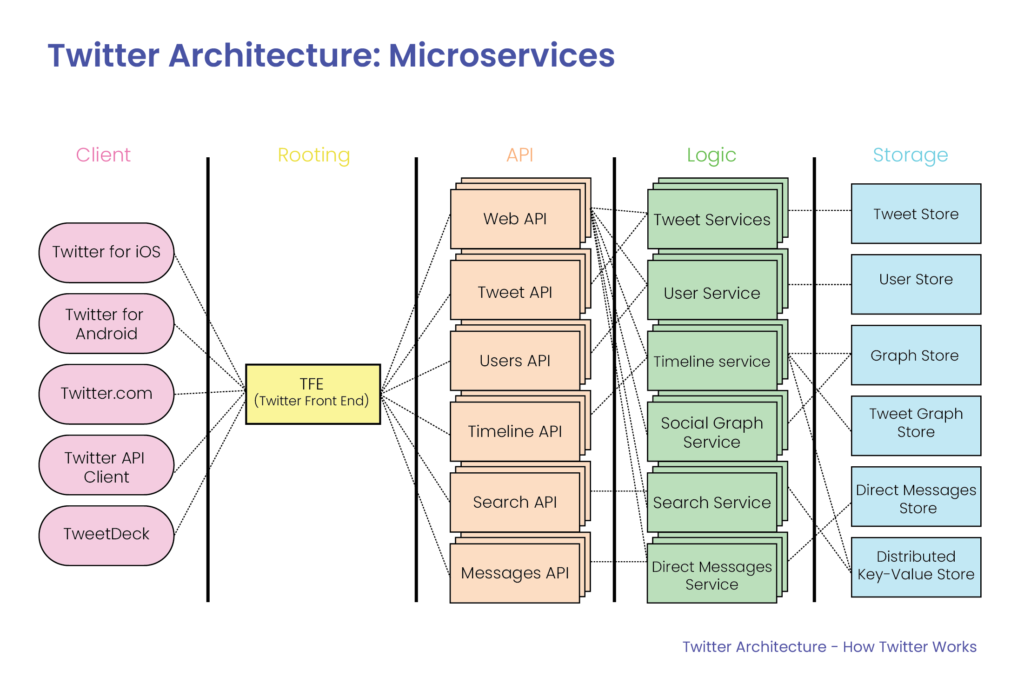
Tweet API uses TweetyPie: tweet object.
User API uses Gizmoduck: Used to keep a track of the user, it has its own cache.
Search API uses EarlyBird, it’s a modified version of Lucene. when a tweet comes in they have a system called Ingester, which tokenize, figure-out features, and everything that can be used as an index for Earlybird.
2020: Data Protection compliance is one of the major work that most of the data companies are working on. Kubernetes, Kafka, and GCP are going to be a part of this architecture.