When we start communicating with a machine there is only one issue machine never understand different categories by name. If we tell a machine the colour of a balloon is red it will not understand ‘Red’ rather than it will keep it as 255,0,0 0r 1,0,0 it means it encodes it in its own mother tongue and it is numeric. As if we talk with an alien about the balloon it will understand in their own mother tongue. Embedding is similar to it but when we say embedded we mean to say we are encoding a subset in a superset of words. Word Embedding is the collective name for a set of language modelling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers.
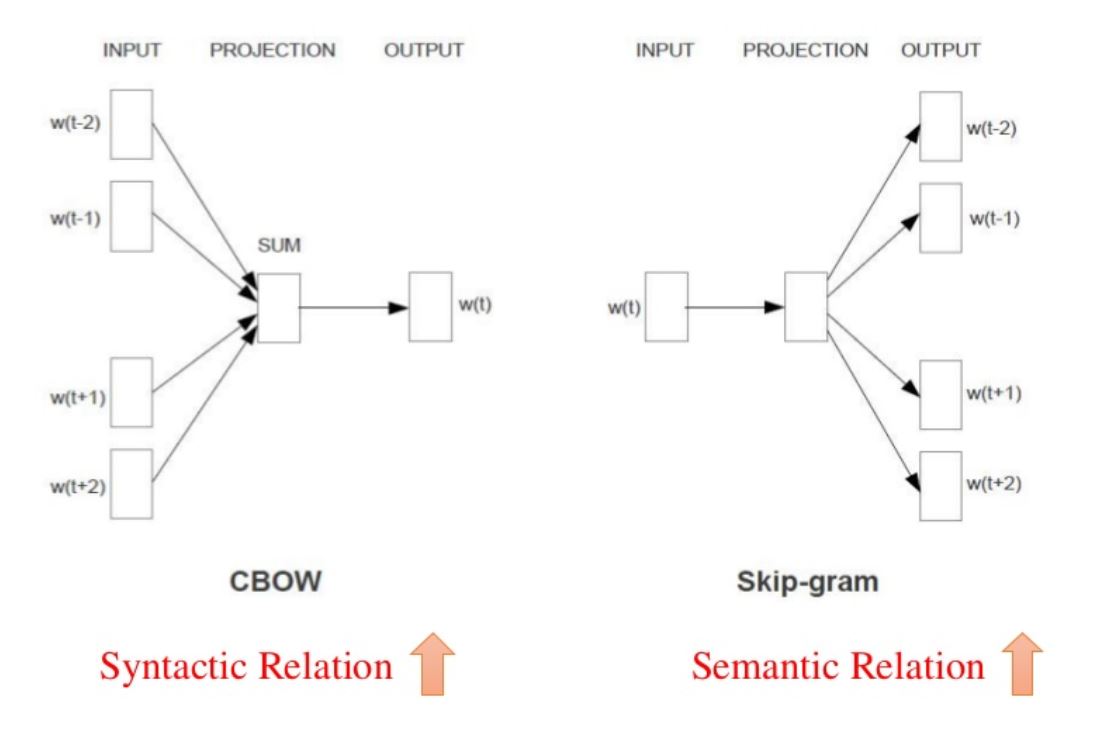
Word2Vec is one of the most common word embedding mode developed in google. Word2vec can utilize either of two model architectures to produce a distributed representation of words: continuous bag-of-words (CBOW) or continuous skip-gram. In the continuous bag-of-words architecture, the model predicts the current word from a window of surrounding context words. The order of context words does not influence prediction (bag-of-words assumption). In the continuous skip-gram architecture, the model uses the current word to predict the surrounding window of context words. The skip-gram architecture weighs nearby context words more heavily than more distant context words. According to the authors’ note, CBOW is faster while skip-gram is slower but does a better job for infrequent words.
Another embedding is LSA, this assumes that words that are close in meaning will occur in similar pieces of text (the distributional hypothesis). A matrix containing word counts per paragraph (rows represent unique words and columns represent each paragraph) is constructed from a large piece of text and a mathematical technique called singular value decomposition (SVD) is used to reduce the number of rows while preserving the similarity structure among columns. Words are then compared by taking the cosine of the angle between the two vectors (or the dot product between the normalizations of the two vectors) formed by any two rows. Values close to 1 represent very similar words while values close to 0 represent very dissimilar words.
Another is Glove, GloVe is an approach to marry both the global statistics of matrix factorization techniques like LSA with the local context-based learning in Word2Vec. Rather than using a window to the local context, GloVe constructs an explicit word-context or word co-occurrence matrix using statistics across the whole text corpus. The result is a learning model that may result in generally better word embeddings.
there are different encoding and embedding techniques like:
Encoding:
1-Find and replace: a manual approach to find and replace a categorical value to a numerical one.
2-Label Encoding: It is similar to the prior approach but its fully automatic.
3-One Hot Encoding: This approach will convert a categorical set of values to columns and assign 0 or 1 to each value. in sklearn we use labelBinarizer.
4-Custom Binary encoding: This process will combine many conditions and give a output in binary format.
5-Backward Difference Encoding
4-Polynomial Encoding.
Embedding:
Word2Vec: A bag of word approach.
LSA: A matrix with cosine approach.
Glove: The Global Vectors for Word Representation, or GloVe, the algorithm is an extension to the Word2Vec method for efficiently learning word vectors, developed in Stanford.
References:
http://pbpython.com/categorical-encoding.html
https://en.wikipedia.org/wiki/Word_embedding
https://en.wikipedia.org/wiki/Latent_semantic_analysis
https://en.wikipedia.org/wiki/Word2vec